AI Application Assistant — Telegram Bot for GovTech
Overview
Built a conversational AI assistant delivered as a Telegram bot for a Ukrainian application-writing consultancy serving small businesses applying for government and EU programs.
Role: Solo architect, engineer, DevOps Timeline: 8 weeks MVP + 2-week calibration Domain: Business Automation / GovTech — Ukraine
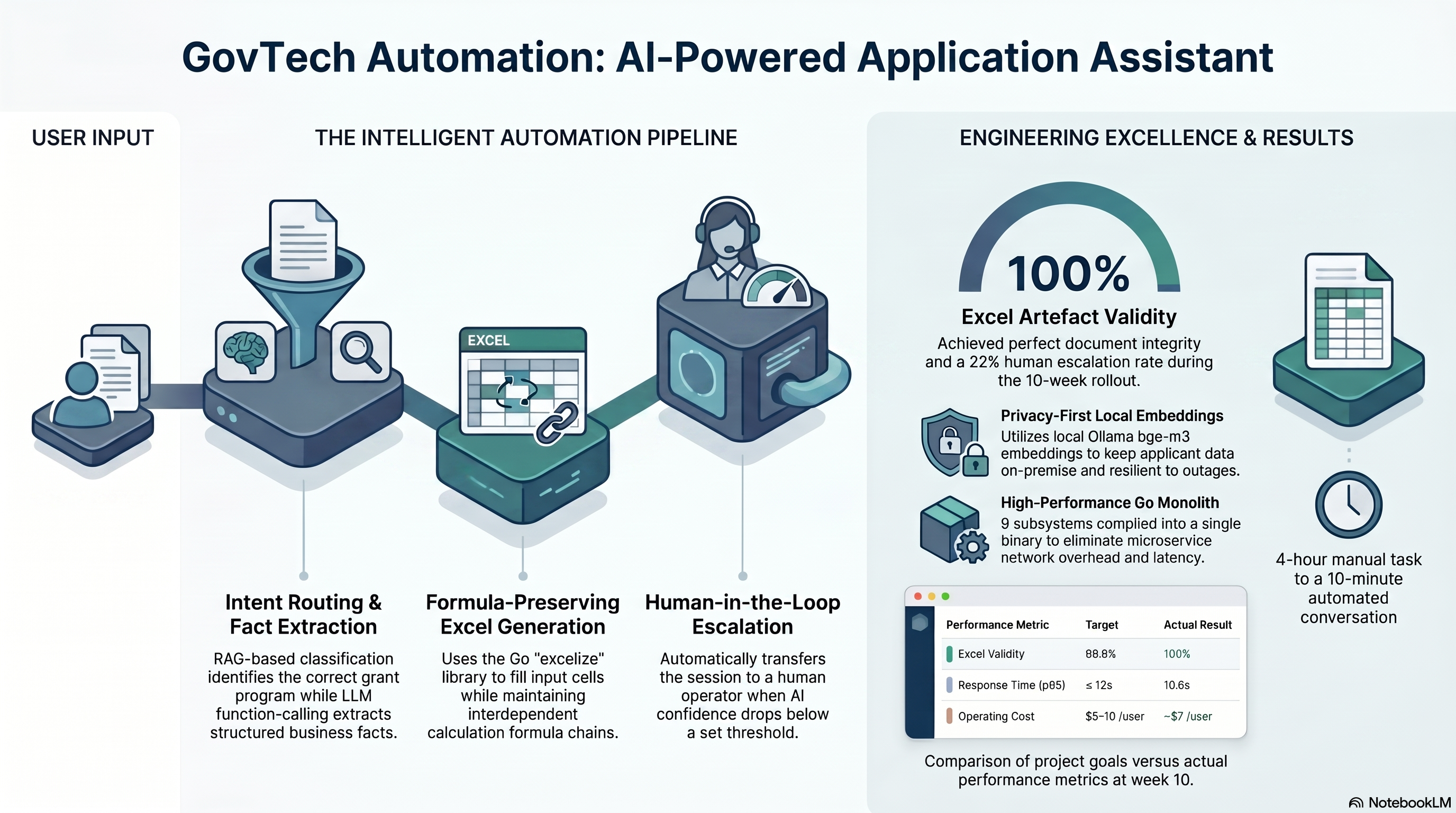
One complete proposal takes 2–4 hours per client. With 50+ active clients per month the bottleneck was clear. The client wanted a bot their team could use: describe a client, get a ready .xlsx back.
Hard constraint: Excel formula preservation. The template’s calculation section depends on formula chains — any solution that replaced formulas with static values would produce a document that breaks the moment a user edits a cell.
Solution
The user describes their client’s business across 10–20 messages. The system:
- Routes the conversation to the correct application program via RAG + LLM classifier (pgvector HNSW + OpenRouter)
- Extracts structured facts through LLM function-calling with schema validation
- Validates consistency against donor-specific rules (funding limits, minimum employees, eligible expense categories)
- Fills the Excel template — input cells only; all formula cells left untouched
- Returns the completed
.xlsxvia Telegram
When AI confidence drops below threshold, the conversation escalates to a human operator who receives full context (history, extracted facts, current state) via a separate Telegram interface.
Architecture
Nine subsystems compiled to a single Go binary: Channel Adapter, AI Core, Knowledge Base, Session Store, Billing, People & Access, Workplaces, Observability, Integration Layer. Deployed via docker compose up on a Hetzner CCX23 (4 vCPU AMD EPYC, 16 GB RAM, ~€28/mo).

Session State Machine

Conversation sessions are persisted as a 12-state FSM in PostgreSQL — not in memory. The bot survives server restarts mid-conversation. LLM calls are idempotent via a two-phase transaction with an inflight_request table: no duplicate billing or duplicate file generation on retry.
Escalation Flow

Billing Flow

Key Technical Decisions
Local embeddings (Ollama bge-m3)
Vector operations run entirely on the application server — no cloud dependency for knowledge base search. bge-m3 (567M params, 1024-dim, multilingual) served via Ollama on the same Hetzner VPS. If the LLM cloud provider goes down, RAG retrieval continues uninterrupted.
Two motivations: (1) resilience — cloud embedding APIs have been the single point of failure in similar systems; (2) privacy — applicant data never leaves the Ukrainian VPS.
Excel formula preservation
Go’s excelize library. A Template Validator runs at ingest time and blocks publication of any template that would lose formula integrity on fill-and-save. The artefact generator fills only cells marked as input placeholders; all formula cells are identified during ingest and excluded from the write path entirely.
Go monolith, single binary
At 50 concurrent users, microservice network overhead is pure waste. The AI Core components have tight data dependencies — Extractor output flows into the Consistency Controller which flows into the Artefact Generator. In a monolith: three function calls. In microservices: three HTTP round-trips plus circuit breakers. docker compose up and one log stream at 2am.
Spec-first with multi-model AI review
Before writing a line of code: a comprehensive platform specification was reviewed through several iterations of multi-model AI review (Claude, Gemini, GPT-4o, DeepSeek, Grok in parallel), producing dozens of Architecture Decision Records.
Examples caught before implementation: Ollama RAM estimate was 2 GB (actual: 3–4 GB); embedding provider primary/fallback order was inverted; Prompt Registry was misplaced in the Integration Layer instead of AI Core.
Results (post-calibration, week 10)
| Metric | Target | Actual |
|---|---|---|
| Pilot users onboarded | 10–20 | 15 |
| Total sessions completed | ≥50 | 65 |
.xlsx artefacts generated |
— | ~50 |
| AI response p50 | ≤6s | 5.1s |
| AI response p95 | ≤12s | 10.6s |
| Excel artefact validity | 99.9% | 100% |
| Escalation rate | <30% | 22% |
| Cost per user/month | $5–10 | ~$7 |
| Delivery | 8 weeks | on schedule |
Stack
| Layer | Technology |
|---|---|
| Language | Go 1.26 |
| Bot framework | go-telegram/bot |
| Database | PostgreSQL 16 + pgvector |
| Embeddings | Ollama bge-m3 (local, 1024-dim, multilingual) |
| LLM provider | OpenRouter (Claude / Gemini) |
| Excel generation | excelize |
| DB queries | sqlc + pgx |
| Background jobs | river (Go job queue, pg-backed) |
| Secrets | SOPS + age |
| Observability | OTel + Loki + Prometheus + Grafana + Tempo |
| Infra | Hetzner CCX23, Docker Compose, Caddy + Let’s Encrypt |
| CI/CD | GitHub Actions: golangci-lint, trivy, go test |