«…більшість питань і суперечок, що бентежать людство, залежать від сумнівного і невизначеного вживання слів або (що те саме) невизначених понять…»
– Джон Локк, Дослід про людське розуміння, Послання до читача (1690)
💡 Про що мова?
В цьому році з’явилося багато термінів, які описують новий інструмент розробки – ШІ.
Одразу, як завжди, почалися дискусії про смак різноколірних олівців, бо одні вважають що від цього можна отримувати задоволення, а інші, що можна тільки для розмноження та й то лише після благословіння церкви.
В принципі можна взяти будь які правила або найкращі практики розробки чи інженерії та замінити там назву будь якого інструменнту на “ШІ” і можеш лупашити ними опонентів прямо в тім’ячко.
Поки бажаючі знавці обмацують цього слона і сперечаються про те, що вони намацали чи відчули, спробуємо визначитися з термінологією.
Треба щось просте і зрозуміле, щоб одразу тицьнути туди на мапі де ми зараз є.
Я теж вмію в розумні слова і тому спробуємо парадигмальний підхід.
Далі – без іронії. Спробуємо зафіксувати робочі визначення.
Мета цього документу – не оцінювати ШІ як “добре / погано”, а дати спільну мову для обговорення: що саме ми зараз робимо, який рівень ризику приймаємо, і які практики доречні у вибраному підході.
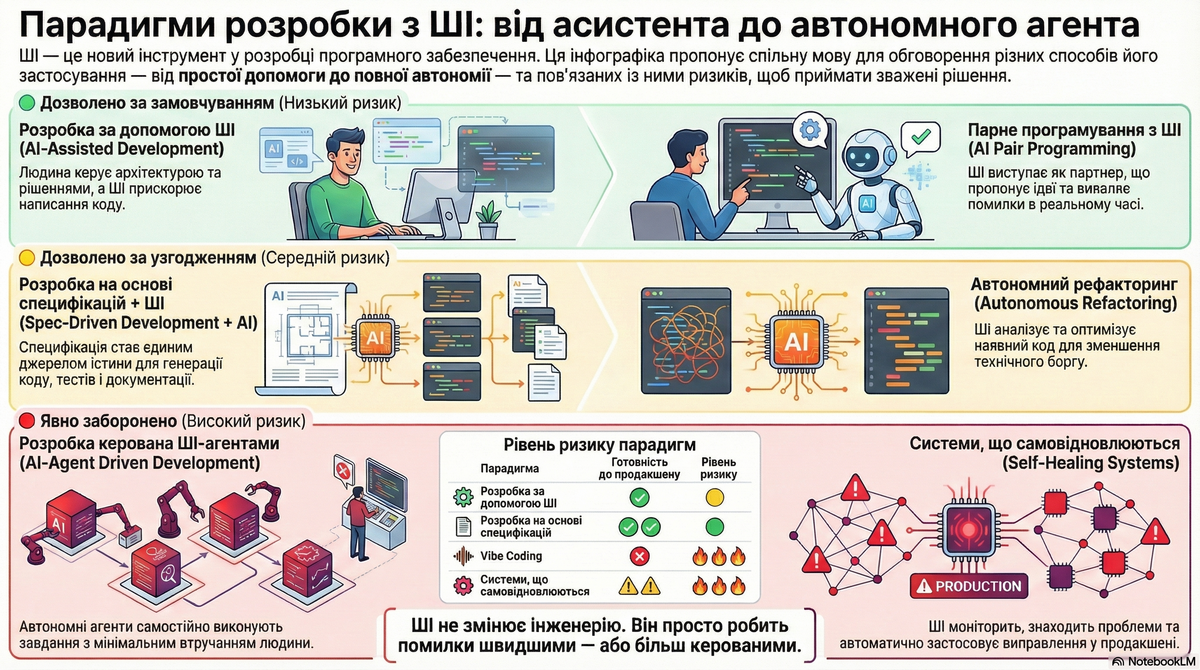
🧩 Парадигми: короткі описи
🔍 Vibe Coding
Vibe Coding – це підхід, при якому розробник описує бажану функціональність мовою, зрозумілою для людини, і генерує код за допомогою ШІ без детального перегляду або редагування результату. Акцент робиться на експериментуванні, швидкому прототипуванні та довірі до ШІ, а не на ручному написанні або перевірці кожного рядка коду.
Намір → ШІ → Код
- ШІ пише код на основі наміру високого рівня
- Мінімальний перегляд, мінімальна структура
- Максимальна швидкість, максимальний ризик
Використовувати, коли
- Прототипи
- Демо-версії
- Спайки
- Одноразовий код
Ніколи не використовувати для
- Продакшен систем
- Основної логіки
- Шляхи, чутливі до безпеки
🔍 AI-assisted development
AI-assisted development (AIAD) – це використання інструментів штучного інтелекту для підтримки розробника на різних етапах розробки: від написання коду, тестування та налагодження до оптимізації та автоматизації повторюваних завдань. Розробник залишається активним учасником процесу, а ШІ виступає як помічник, що пропонує ідеї, автоматизує рутину та покращує якість коду.
Розробка під керівництвом людини з використанням ШІ як інструменту
- Людина володіє архітектурою та рішеннями
- ШІ прискорює реалізацію
- Застосовуються стандартні перевірки та тестування
Використовувати, коли
- Написання виробничих функцій
- Підтримка тривалих кодових баз
🔍 AI-Powered Pair Programming
ШІ-помічники працюють разом із розробником у реальному часі, пропонуючи альтернативи, виявляючи помилки, оптимізуючи код та навіть генеруючи нові функції на основі контексту. Такий підхід зменшує час на зневадження та покращує архітектуру проєктів.
Людина ⇄ ШІ в режимі реального часу
- Постійний діалог
- ШІ пропонує, людина вирішує
- Порівнянно з поєднанням програмування з сильним молодшим/середнім розробником
Використовуйте, коли
- Повсякденна розробка
- Вивчення незнайомих кодових баз або мов
🔍 Generative AI for Specification and Design
ШІ використовується для автоматичної генерації архітектурних рішень, діаграм, документації та навіть тестових сценаріїв на основі вимог. Це дозволяє швидко отримати прототип системи та перевірити її на відповідність бізнес-вимогам.
Вимоги → ШІ → Специфікації / Діаграми
- ШІ допомагає до кодування
- Генерує чернетки специфікацій, архітектурних діаграм, планів тестування
- Людина перевіряє та вдосконалює
Використовуйте, коли
- Проектування системи
- Дослідження архітектури
- Ранні етапи планування
🔍 AI-Augmented Spec-Driven Development
AI-Augmented Spec-Driven Development – це парадигма, в якій структуровані специфікації (вимоги, архітектурні обмеження, критерії прийняття тощо) є основним джерелом для генерації коду за допомогою ШІ. Ці специфікації стають єдиним джерелом істини, яке ШІ перетворює на реалізацію, тести та документацію. Такий підхід забезпечує високу узгодженість між вимогами та реалізацією, скорочує ризики помилок і підвищує швидкість розробки.
Специфікація → ШІ → Код + Тести
- Специфікація є джерелом істини
- ШІ генерує код і тести на основі специфікацій
- Найвища передбачуваність і зручність обслуговування
Використовується в таких випадках
- Основна бізнес-логіка
- Фінансові, безпекові або регульовані системи
- Великі кодові бази з тривалим терміном експлуатації
🔍 AI-Driven Development (AIDD)
Це парадигма, де ШІ глибоко інтегрований у всі етапи розробки – від проєктування та написання коду до тестування, оптимізації та навіть розгортання. Розробник і ШІ працюють як партнер, що значно підвищує продуктивність і якість коду.
Людина + ШІ спільно керують процесом
- ШІ бере участь у проектуванні, кодуванні, тестуванні та оптимізації
- Людина залишається відповідальною за стратегію та обмеження
Використовувати, коли
- Команди навмисно впроваджують ШІ в SDLC
- Існують чіткі обмеження та процеси оцінки
🔍 Autonomous Refactoring та Adaptive Coding
ШІ автоматично аналізує та рефакторить код, виявляючи потенційні проблеми, пропонуючи оптимізації та адаптується до змін у проєкті. Такі системи можуть навчатися на великій кількості коду, щоб краще розуміти контекст та вимоги проєкту.
Існуючий код → ШІ → Вдосконалений код
- ШІ рефакторує, оптимізує та зменшує технічний борг
- Працює за суворими правилами та підлягає оцінці
Використовується, коли
- Контрольований рефакторинг
- Оптимізація продуктивності
- Вдосконалення стилю та узгодженості
🔍 Pipeline Synthesis та Security Scanning Orchestration
ШІ може автоматично генерувати конфігурації CI/CD, аналізувати безпеку коду, виявляти технічний борг та пропонувати шляхи його усунення. Це зменшує ризики та прискорює процес розгортання.
Політика → ШІ → CI/CD та автоматизація безпеки
- ШІ генерує та підтримує конвеєри
- Автоматизує сканування безпеки та забезпечення дотримання політик
Використовувати, коли
- Автоматизація DevSecOps
- Зниження операційного ризику
🔍 AI-Agent Driven Development
ШІ-агенти можуть самостійно виконувати певні завдання – від генерації коду за специфікаціями до автоматичного створення тестів, моніторингу та навіть виправлення помилок у продакшені. Це дозволяє створювати самоохоронні системи, які мінімізують втручання людини.
Мета → ШІ-агенти → Виконання
- Автономні агенти розкладають та виконують завдання
- Мінімальне втручання людини
Використовувати з особливою обережністю
- Внутрішні інструменти
- Чітко обмежені завдання автоматизації
🔍 Self-Healing Systems
ШІ-агенти моніторять систему у продакшені, виявляють проблеми, генерують латки та автоматично їх застосовують, забезпечуючи високу надійність та мінімізуючи простої.
Сигнали під час виконання → ШІ → Виправлення → Розгортання
- ШІ контролює продакшен та автоматично застосовує виправлення
- Найвища автономність, найвищий ризик
Не рекомендується за замовчуванням
- Тільки з суворими запобіжними заходами
- Тільки для некритичних систем
📊 Порівняльна таблиця
| Парадигма |
Хто веде |
Джерело істини |
Типове застосування |
Готовність до продакшену |
Ризик |
| Vibe Coding |
ШІ |
Prompt |
Прототипи, demo |
❌ |
🔥🔥🔥 |
| AI-assisted Dev |
Людина |
Код |
Продакшн-фічі |
✅ |
🟡 |
| AI Pair Programming |
Людина + ШІ |
Код |
Щоденна розробка |
✅ |
🟡 |
| Generative Spec & Design |
Людина |
Spec |
Архітектура, планування |
⚠️ |
🟡 |
| Spec-Driven + AI |
Специфікація |
Spec |
Core-системи |
✅✅ |
🟢 |
| AI-Driven Dev |
Людина + ШІ |
Mixed |
End-to-end dev |
✅ |
🟡 |
| Autonomous Refactoring |
ШІ |
Code + Rules |
Техборг, cleanup |
⚠️ |
🟡 |
| Pipeline & Security AI |
Policy |
Policy |
CI/CD, Security |
✅ |
🟡 |
| AI-Agent Driven Dev |
ШІ-агенти |
Goal / Policy |
Автоматизація |
⚠️ |
🔥🔥 |
| Self-Healing Systems |
ШІ |
Runtime signals |
Ops / reliability |
⚠️⚠️ |
🔥🔥🔥 |
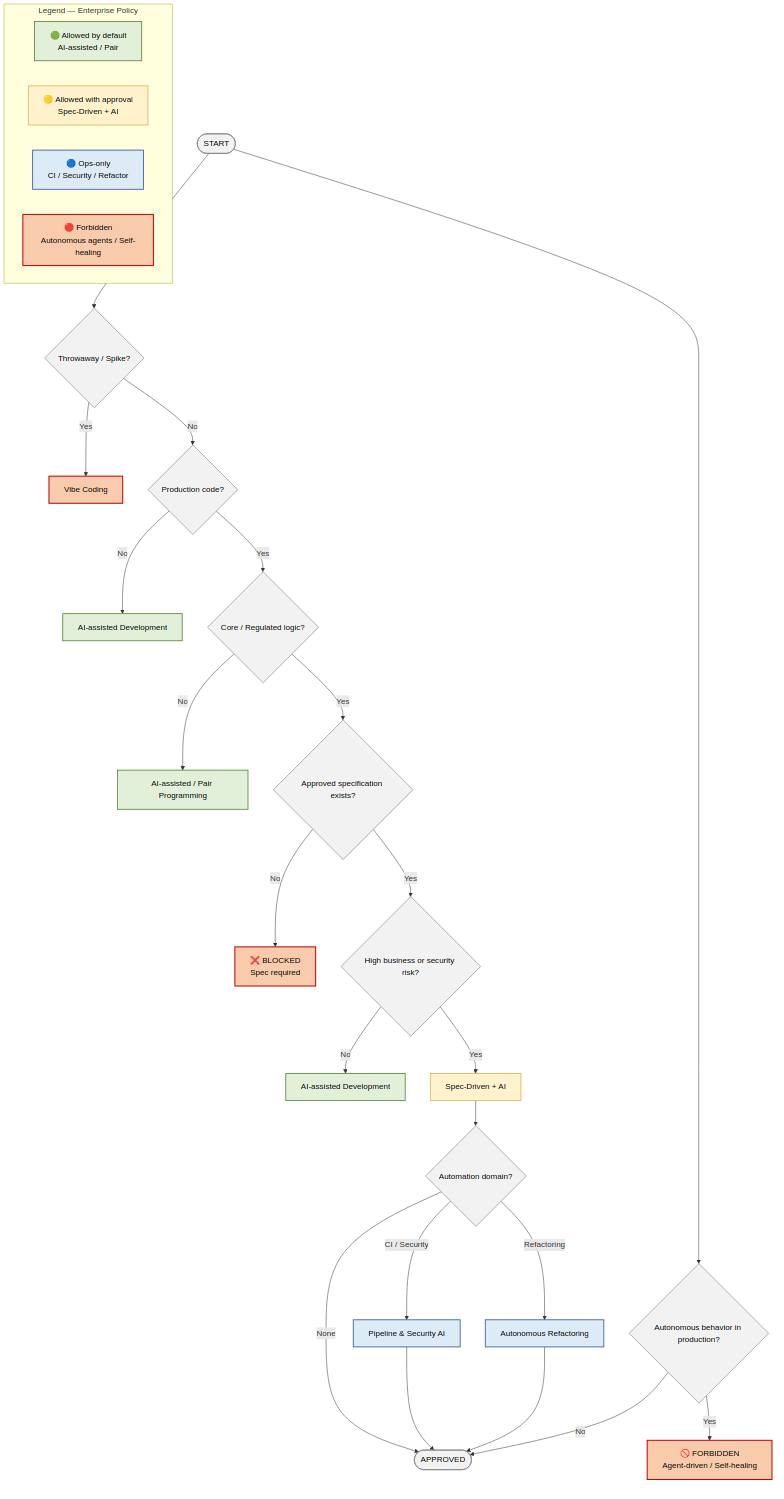
🌳 Парадигми розробки за допомогою ШІ – Дерево рішень
Дерево рішень про те, про що в будь-який конкретний момент йдеться.
Це дерево визначає режим розробки, а не конкретний інструмент.
🏢 Політики
🟢 Дозволено за замовчуванням
- Розробка за допомогою ШІ
- Парне програмування за допомогою ШІ
- Рефакторинг з рев’ю
🟡 Дозволено за умови явного схвалення
- Розробка на основі специфікацій за допомогою ШІ
- Код, згенерований ШІ, у базовій логіці
- Будь-який ШІ у регульованих доменах
🔵 Тільки для операційної діяльності
- Генерація CI/CD
- Сканування безпеки
- Забезпечення дотримання залежностей та політики
🔴 Явно заборонено
- Розробка на основі ШІ-агентів у продакшені
- Системи самовідновлення
- Автономні зміни у продакшені без схвалення людини
В цілому
ШІ не змінює інженерію. Він лише робить її помилки швидшими – або керованішими.
]]>