
Професійний веб-скрейпер
Короткий огляд
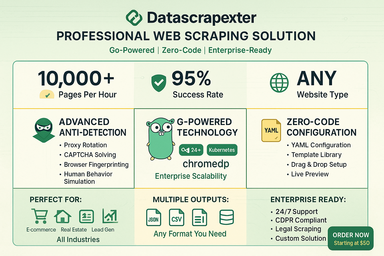
Професійний фреймворк для веб-скрейпінгу на Go із захистом від виявлення, розпізнаванням капчі, ротацією проксі та розподіленою обробкою. Вивід структурованих даних у JSON, CSV або базу даних через гнучкі конфігурації YAML/JSON.
DataScrapexter — це високопродуктивна платформа для веб-скрейпінгу на основі Go, призначена для вилучення даних з будь-яких веб-сайтів із подоланням складних засобів захисту від скрейпінгу. Побудована на Go 1.24+ з потужним стеком технологій (Colly, Goquery, chromedp), вона пропонує чотири пакети, адаптовані до різноманітних потреб:
- Базовий пакет: Доступне рішення з відкритим кодом для простих статичних сайтів, ідеальне для аматорів та невеликих проєктів.
- Стандартний пакет: Розширені функції, зокрема рендеринг JavaScript та ротація проксі для малих і середніх підприємств, які працюють з динамічними сайтами.
- Преміум пакет: Готовий до виробничого використання з розширеними засобами захисту від виявлення, масштабованістю та моніторингом для професійних користувачів і підприємств.
- Розширений пакет: Платформа корпоративного рівня з адаптацією на основі ШІ, відповідністю вимогам і власними інтеграціями для складних великомасштабних операцій.
Додаткові опції включають розробку кастомних функцій, консалтинг та преміум підтримку.
Примітка: Деталі щодо вартості преміум пакетів та кастомних функцій доступні за посиланням “I will develop web scraping solutions for data extraction”.
Детальний огляд
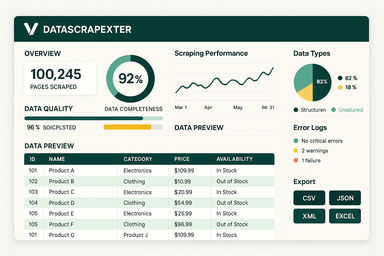
Опис продукту
DataScrapexter — це модульне, масштабоване рішення для веб-скрейпінгу на Go 1.24+, розроблене для роботи з різноманітними веб-сайтами — від статичного HTML до важких JavaScript односторінкових додатків (SPA) — з обходом передових засобів захисту від скрейпінгу. Платформа поєднує конфігурованість (через YAML/JSON та Viper) із досконалими механізмами захисту від виявлення (chromedp, Rod, 2Captcha) та надійним конвеєром обробки даних (GORM, Kafka). Підтримуються виводи в декількох форматах (JSON, CSV, Excel, бази даних) та інтеграція з хмарними сервісами (AWS, Google Cloud).
Деталі пакетів
1. Базовий пакет
Цільова аудиторія: Аматори, індивідуальні розробники, невеликі стартапи та аналітики даних.
Ключові функції:
- Базовий скрейпінг: HTTP-клієнт (net/http) з Goquery для вилучення даних на основі CSS-селекторів.
- Захист від виявлення: Базова ротація User-Agent (50+ підписів браузерів), фіксоване обмеження швидкості (затримки 1-5 секунд) та ручна підтримка HTTP-проксі.
- Конфігурація: Визначення сайтів на основі YAML, керовані через Viper.
- Вивід: Експорт даних у форматах JSON та CSV.
- CLI: Інтерфейс командного рядка на основі Cobra для зручного використання.
- Логування: Структуроване логування за допомогою logrus.
Приклад використання: Фрілансер-аналітик даних вилучає списки товарів з 10 статичних e-commerce сайтів для маркетингових досліджень. Він створює конфігурацію YAML для цільових назв продуктів та цін:
name: "ecommerce_site"
base_url: "https://example-shop.com"
fields:
- name: "title"
selector: "h2.product-title"
type: "text"
- name: "price"
selector: ".price"
type: "text"
rate_limit: 2s
Приклад CLI:
# Запуск скрейпера з конфігураційним файлом
datascrapexter scrape --config configs/ecommerce_site.yaml --output products.json
Обмеження:
- Немає підтримки рендерингу JavaScript.
- Потрібна ручна конфігурація проксі.
- Обмежені механізми відновлення після помилок.
- Немає можливостей розподіленої обробки.
2. Стандартний пакет
Цільова аудиторія: Малий та середній бізнес, SaaS-стартапи та професійні команди з обробки даних.
Ключові функції (розширює Базовий):
- Рендеринг JavaScript: Інтеграція chromedp для обробки сайтів на React, Vue, Angular, AJAX-запитів та нескінченного прокручування.
- Розширений захист від виявлення: Автоматична ротація проксі з моніторингом стану, базова рандомізація відбитків браузера та виявлення CAPTCHA.
- Обробка даних: Очищення тексту, валідація полів, дедублювання та підтримка баз даних (SQLite, PostgreSQL).
- Конфігурація: Система повторно використовуваних шаблонів, управління секретами через змінні середовища та гаряче перезавантаження конфігурацій.
- Пул браузерів: Керовані екземпляри Chrome для одночасних завдань скрейпінгу.
Приклад CLI:
# Запуск скрейпера з ротацією проксі та виводом до бази даних
datascrapexter scrape --config configs/competitor_site.yaml --output postgres://user:pass@localhost:5432/dbname --proxy-list proxies.txt
Обмеження:
- Потрібне ручне розв’язання CAPTCHA.
- Обмежена масштабованість для великих наборів даних.
- Відсутній корпоративний моніторинг та аналітика.
3. Преміум пакет
Цільова аудиторія: Професійні сервіси, середні компанії та підприємства.
Ключові функції (розширює Стандартний):
- Розширений захист від виявлення: Інтеграція з 2Captcha/Anti-Captcha для автоматизованого розв’язання CAPTCHA, підміна canvas/WebGL, симуляція людської поведінки та рандомізація TLS-відбитків (JA3/JA4).
- Моніторинг та спостережуваність: Збір метрик Prometheus, профілювання pprof, моніторинг стану в реальному часі та детальна аналітика помилок.
- Масштабованість: Розподілена обробка з координацією Redis, пули воркерів, пріоритетне планування завдань та можливості автомасштабування.
- Корпоративні функції: Веб-панель для конфігурації та моніторингу, RESTful API, контроль доступу на основі ролей (RBAC) та комплексне логування аудиту.
Приклад CLI:
# Запуск розподіленого завдання скрейпінгу з моніторингом
datascrapexter scrape --config configs/news_site.yaml --output kafka://localhost:9092/news-topic --workers 10 --monitor prometheus://localhost:9090
4. Розширений пакет
Цільова аудиторія: Великі підприємства, організації, що керуються даними, та технологічні інноватори.
Ключові функції (розширює Преміум):
- Адаптація на основі ШІ: Правила вилучення, згенеровані машинним навчанням, автоматичне виявлення та адаптація до змін макету сайту, класифікація контенту на основі ШІ та оцінка якості даних.
- Розширена обробка контенту: Обробка природної мови (NLP) для контекстно-залежного вилучення, оптична розпізнавання символів (OCR) для даних на основі зображень та семантичне відображення зв’язків.
- Розумний захист від виявлення: Симуляція людської поведінки на основі МН, адаптивне налаштування часу та виявлення аномалій у реальному часі.
- Масштабованість: Автомасштабування на основі Kubernetes, багатовузлова координація з Redis Streams та пріоритетні черги завдань.
Приклад CLI:
# Запуск завдання скрейпінгу з розширеним ШІ та адаптивними правилами
datascrapexter scrape --config configs/reviews.yaml --output bigquery://project:dataset.reviews --ai-adapt --workers 20
5. Розширений — Кастомні функції
Цільова аудиторія: Підприємства з унікальними вимогами, системні інтегратори та стратегічні клієнти.
Кастомні опції:
- Унікальний захист від виявлення: Кастомні стратегії відбитків та конфігурації проксі для конкретних цільових сайтів.
- Кастомні інтеграції: Безшовна з’єднання з CRM, BI-інструментами або власними системами через REST/GraphQL API або потоки Kafka.
- Автоматизація відповідності: Адаптовані робочі процеси відповідності GDPR/CCPA, включаючи автоматизовану анонімізацію даних та звітність.
- Консалтингові послуги: Конфігурація за участі експертів, оптимізація продуктивності та навчання персоналу.
- Приватні розгортання: Локальне або VPC-розгортання з архітектурою нульової довіри.

Додаткові опції
- Преміум підтримка: Цілодобова виділена підтримка з угодами про рівень обслуговування (SLA) та управлінням акаунтом.
- Торговий майданчик конфігурацій: Шаблони від спільноти для швидкого розгортання на популярних веб-сайтах.
- Навчальна платформа: Інтерактивні підручники, сертифікати та найкращі практики для навчання команд.
- Професійні послуги: Повне налаштування, налаштування продуктивності та постійне обслуговування.
Чому обрати DataScrapexter?
- Продуктивність: Легковагові горутини Go забезпечують 10 000+ сторінок/годину при менш ніж 512 МБ пам’яті на екземпляр.
- Обхід захисту: Передовий захист від виявлення (chromedp, Rod, 2Captcha) забезпечує успішність 95%+ на захищених сайтах.
- Гнучкість: Конфігурація YAML/JSON підтримує будь-який тип веб-сайту — від статичного до SPA — з виводом у декількох форматах.
- Масштабованість: Архітектура, готова до Kubernetes, з автомасштабуванням та розподіленою обробкою для масивних робочих навантажень.
- Відповідність: Вбудована відповідність GDPR/CCPA, дотримання robots.txt та логування аудиту забезпечують етичний скрейпінг.
DataScrapexter дає змогу користувачам ефективно, етично та у масштабі вилучати веб-дані, пропонуючи адаптовані пакети для кожного — від аматорів до глобальних підприємств.