AI Voice Agent — Micromobility Customer Support
Overview
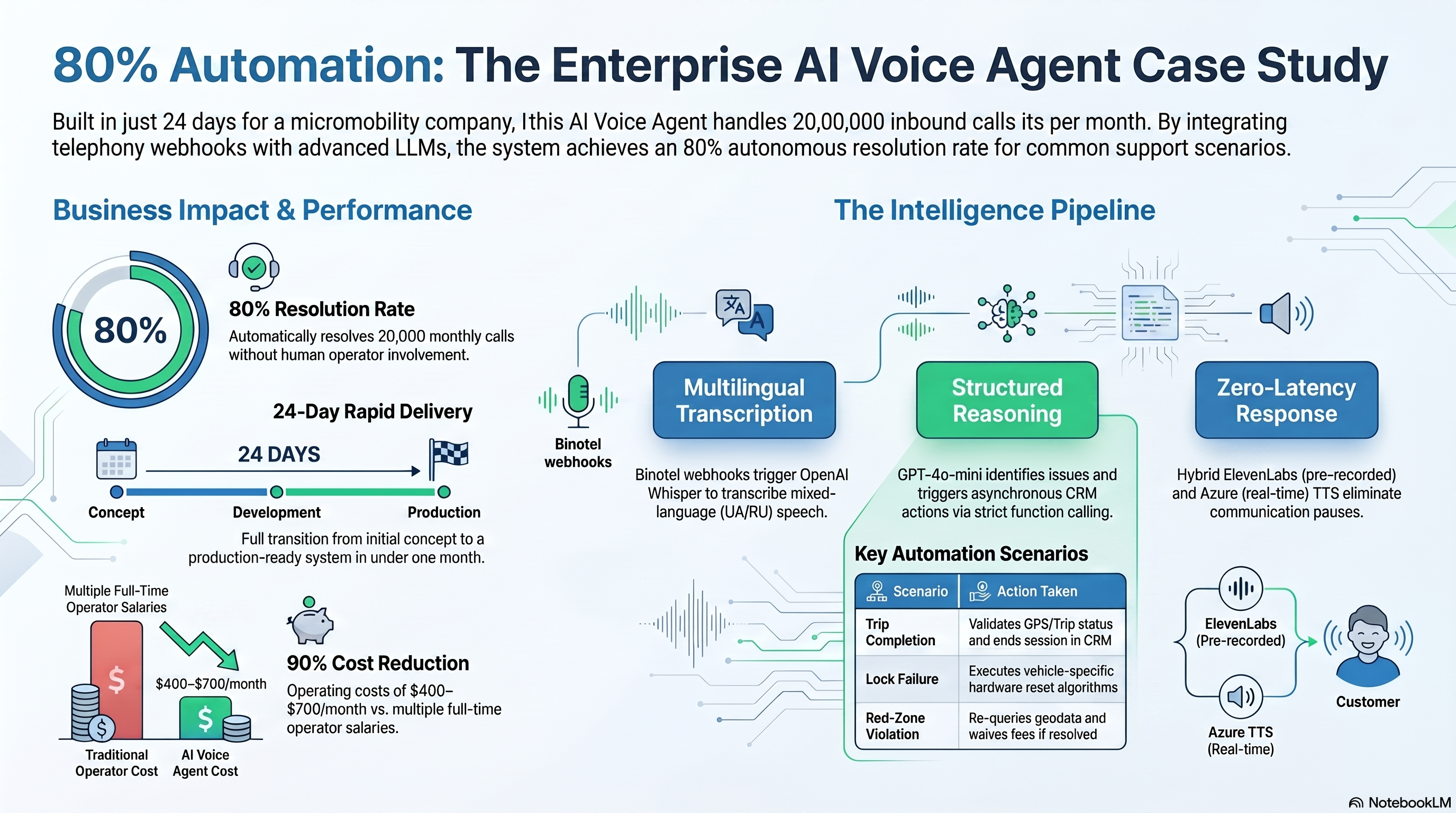
Built a voice AI agent that automates repetitive customer support calls for a micromobility company processing ~20,000 inbound calls per month. Delivered in 24 days.
Operators spent 80% of their time on four recurring scenarios: trip completion issues, lock failures, red-zone violations, and app freezes. The bot now handles all four autonomously — querying the CRM in real time, taking action, and closing the call. When a situation falls outside the script, it transfers to a human operator with full call context.
Result: ~80% of calls resolved without operator involvement.
Architecture
Binotel webhook → Whisper STT (UA/RU) → GPT-4o-mini → CRM API
↓
ElevenLabs (pre-recorded) / Azure TTS (real-time)
- Customer calls → Binotel fires a webhook to the Go server
- Bot plays greeting (ElevenLabs, pre-recorded)
- Customer speaks → Whisper transcribes (UA/RU)
- GPT-4o-mini identifies the problem and selects next action via function calling
- CRM query runs async (vehicle location, zone status, trip status)
- Bot executes action or asks a follow-up question
- Resolved → ends call; unresolved → transfers to operator

Call Flows
Trip completion

Lock won’t open (bicycle vs. scooter)

Red-zone violation

App frozen

Key Challenges
Pipeline latency. STT + LLM + TTS in sequence produced 3–5 second pauses — unacceptable for voice. All fixed phrases (greeting, confirmations, clarification requests) pre-generated via ElevenLabs and cached. Azure TTS only for dynamic responses. CRM requests run async while the bot is still speaking.
Session state between webhooks. Binotel sends a separate POST per event (customer response, DTMF, call end). Conversation state stored in Redis keyed by call_id with 30-minute TTL.
Mixed-language input. Customers switch freely between Ukrainian and Russian — sometimes mid-sentence. Whisper with explicit language prompting and post-processing normalization of numerals and vehicle codes resolved ~95% of cases.
LLM hallucinating actions. GPT-4o-mini could misclassify a request or invent an action outside the defined scenarios. Switched to structured outputs + function calling with a strict action set: end_trip, restart_transport, create_ticket, transfer_to_operator. LLM selects from the list; cannot invent.
Lock logic — bicycle vs. scooter. Two vehicle types with different 5–7 step algorithms where each step depends on the previous result. Instead of a monolithic prompt — separate state machine per vehicle type; LLM only decides the current step, not the full scenario logic.
Peak load. ~30–40 concurrent calls at peak. One goroutine per call, worker pool for CRM requests with rate limiting. Deployed on a 4 vCPU / 8 GB RAM VPS.
False geofence triggers. CRM geodata updates with delay — customer already returned the vehicle but the system still shows red zone. Re-query after 10 seconds; if the second query confirms the customer’s location — end the trip and waive the extra minutes.
Key Design Decisions
| Decision | Why |
|---|---|
| GPT-4o-mini over GPT-4 | Sufficient quality for structured scenarios, 10× lower cost |
| ElevenLabs pre-recorded + Azure TTS real-time | ElevenLabs: high-quality voice for fixed phrases (generated once); Azure: dynamic responses in real time |
| Binotel webhook without own SIP server | Binotel manages SIP infrastructure; webhook API handles any IVR complexity |
| Function calling over free-form prompts | Deterministic behavior, impossible to act outside defined boundaries |
| State machine for complex scenarios | Predictable logic, easy to test, LLM doesn’t hold full scenario context |
Results
- ~80% of calls resolved without operator involvement
- Operating costs: ~$400–700/month (vs. full-time operator salary)
- Response time: instant, no queue
- Delivered in 24 days
- Coverage: 4 main scenarios + edge cases (false geofences, code-switching, uncommon phone models)
Stack
Go · Binotel Webhook API · OpenAI Whisper · GPT-4o-mini · ElevenLabs TTS · Azure Cognitive Services TTS · Redis · PostgreSQL · VPS (Ubuntu)