AI-голосовий агент — підтримка клієнтів мікромобільності
Огляд
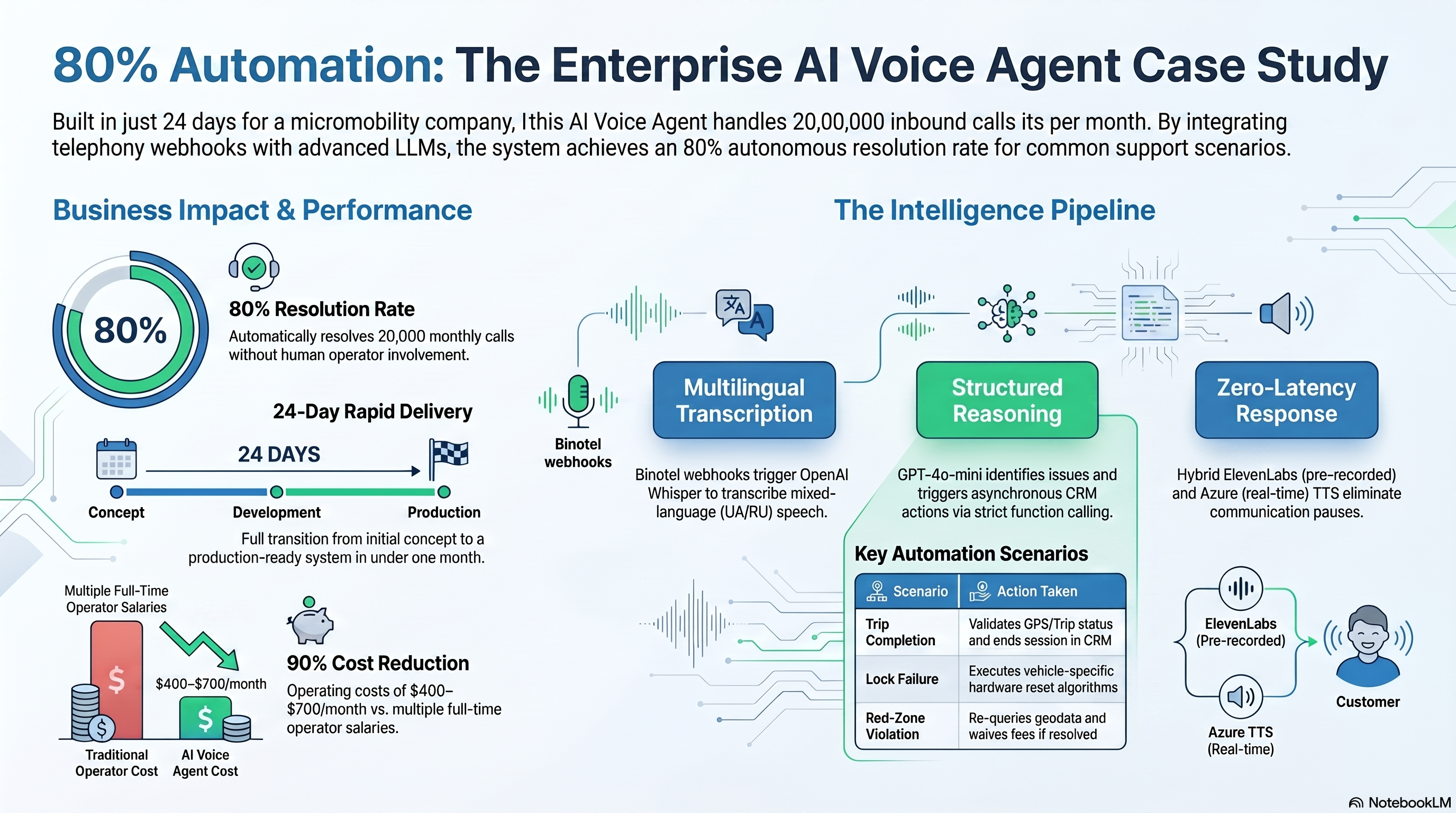
Голосовий AI-агент для автоматизації повторюваних дзвінків до служби підтримки компанії мікромобільності, яка обробляла ~20 000 вхідних дзвінків на місяць. Реалізовано за 24 дні.
Оператори витрачали 80% часу на чотири типові сценарії: проблеми із завершенням поїздки, несправності замка, порушення червоної зони та зависання застосунку. Бот тепер обробляє всі чотири самостійно — запитує CRM у реальному часі, виконує дію та завершує дзвінок. Якщо ситуація нестандартна — плавно передає оператору з повним контекстом розмови.
Результат: ~80% дзвінків закривається без участі оператора.
Архітектура
Binotel webhook → Whisper STT (UA/RU) → GPT-4o-mini → CRM API
↓
ElevenLabs (pre-recorded) / Azure TTS (real-time)
- Клієнт телефонує → Binotel надсилає webhook на Go-сервер
- Бот відтворює привітання (ElevenLabs, pre-recorded)
- Клієнт говорить → Whisper транскрибує (UA/RU)
- GPT-4o-mini визначає проблему і наступний крок через function calling
- Запит до CRM іде асинхронно (де транспорт, яка зона, статус поїздки)
- Бот виконує дію або задає уточнювальне питання
- Якщо вирішено — завершує дзвінок; якщо ні — передає оператору

Сценарії дзвінків
Завершення поїздки

Замок не відкривається (велосипед / самокат)

Червона зона

Застосунок завис

Що було складно
Затримка пайплайну. STT + LLM + TTS послідовно давали 3–5 сек паузи — неприйнятно для голосового бота. Всі стандартні репліки (вітання, підтвердження, прохання уточнити) згенеровані через ElevenLabs заздалегідь і кешовані. Azure TTS — лише для динамічних відповідей. CRM-запити йдуть асинхронно поки бот ще говорить.
Стан між webhook-викликами. Binotel надсилає окремий POST на кожну подію (відповідь клієнта, DTMF, завершення дзвінка). Стан розмови зберігаємо в Redis з ключем call_id і TTL 30 хв.
Змішана мова. Клієнти вільно переходять між українською та російською — іноді в одному реченні. Whisper з явним language промптом і post-processing нормалізація числівників та кодів транспорту вирішили ~95% випадків.
LLM вигадує дії. GPT-4o-mini міг неправильно класифікувати запит або вигадати дію поза сценарієм. Перейшли на structured outputs + function calling з жорстким переліком: end_trip, restart_transport, create_ticket, transfer_to_operator. LLM вибирає зі списку — не вигадує.
Логіка замка — велосипед vs самокат. Два транспортні засоби мають різні 5–7-крокові алгоритми, де кожен крок залежить від результату попереднього. Замість монолітного промпту — окремий state machine для кожного типу; LLM лише вирішує поточний крок, а не всю логіку.
Пікове навантаження. ~30–40 одночасних дзвінків у пік. Один goroutine на дзвінок, пул воркерів для CRM-запитів з rate limiting. Деплой на VPS 4 vCPU / 8 GB RAM.
Помилкові спрацювання геозони. Геодані в CRM оновлюються із затримкою — клієнт вже повернув транспорт, але система ще показує червону зону. Повторний запит через 10 сек; якщо клієнт стверджує що він на місці і другий запит підтверджує — завершуємо поїздку і анулюємо зайві хвилини.
Архітектурні рішення
| Рішення | Чому |
|---|---|
| GPT-4o-mini замість GPT-4 | Достатня якість для структурованих сценаріїв, вартість у 10× нижча |
| ElevenLabs pre-recorded + Azure TTS real-time | ElevenLabs — якісний голос для фіксованих фраз (генерується один раз); Azure — для динамічних відповідей у реальному часі |
| Binotel webhook без власного SIP-сервера | Binotel сам керує SIP-інфраструктурою; webhook API достатній для будь-якої складності IVR |
| Function calling замість вільного промпту | Детермінована поведінка, неможливо вийти за межі дозволених дій |
| State machine для складних сценаріїв | Передбачувана логіка, легко тестувати, LLM не тримає весь контекст сценарію |
Результати
- ~80% дзвінків закривається без участі оператора
- Операційні витрати: ~$400–700/міс (vs. повна ставка оператора)
- Час реакції: миттєво, без черги
- Доставка за 24 дні
- Покрито: 4 основні сценарії + edge cases (помилкові геозони, code-switching, нестандартні моделі телефонів)
Стек
Go · Binotel Webhook API · OpenAI Whisper · GPT-4o-mini · ElevenLabs TTS · Azure Cognitive Services TTS · Redis · PostgreSQL · VPS (Ubuntu)