Теза статті (один рядок): В епоху автономних ШІ-агентів специфікація — це не джерело істини, а джерело розподілу можливих реалізацій; вона стає інженерним артефактом лише тоді, коли її допуск виміряний і вписаний у бюджет точності.
Акт I: Попередні ласки (The Sacred Artifact)
Протягом десятиліть у колі системних архітекторів та інженерів вибудовувався непохитний культ: Єдине Джерело Істини (Single Source of Truth). Ми молилися на цей концепт, як на священний артефакт. Ми навчилися малювати вилизані, детерміновані SysML-моделі, структурувати вимоги бізнесу в красиві Markdown-специфікації та фіксувати архітектурні рішення в RFC.
Коли такий документ лежить у репозиторії, команда відчуває тотальний контроль. Ми віримо, що оскільки ідея записана символами на екрані, ми приборкали реальність і зафіксували точні інженерні наміри. Це наша зона комфорту — стерильний світ, де панує ілюзія абсолютної точності й передбачуваності. Ми створюємо текст, закриваємо тікет у Jira і вважаємо, що робота з проектування завершена.
Акт II: Нагнітання (The Cloud of Intent)
Але наступає середина 2026 року, і комерціалізація автономних ШІ-агентів (на кшталт Claude Code чи Cursor) робить жорсткий фінт вухами. Старе детерміноване джерело істини — з нашими схемами, скомпільованим кодом та жорсткими Boundary-лініями — непомітно колапсує у летючі людські «наміри» (intents) та нескінченні розмовні стрими в чатах.
Ми згодовуємо ШІ наше «ідеальне» ТЗ, вважаючи його істиною. Але велика мовна модель читає текст інакше, ніж колега з десятьма роками спільного контексту: вона не має нашого неявного інженерного досвіду, тож там, де людина бачить «простір для імпровізації», модель бачить дірку в контексті. І заповнює її — семплінгом із власного розподілу ймовірностей, видаючи результат з упевненістю професора.
Свята специфікація на наших очах перетворюється на джерело невідомості. ШІ тут працює мультиплікатором хаосу: він бере наш прихований безлад і масштабує його у спагеті-архітектуру швидше, ніж команда встигає це помітити, — у токенах, рядках коду й агент-ітераціях, які людський оператор уже не здатний осягнути чи проаудитувати.
Важливе розмежування, яке загубила індустрія: «туман» специфікації — це не одна хвороба, а щонайменше три різні режими збою:
| Режим збою | Що це | Приклад |
|---|---|---|
| Неоднозначність | Кілька правдоподібних реалізацій одного тексту | «гнучко приймати транзакції» |
| Неповнота | Відсутні обмеження, схеми, критерії приймання | немає схеми Transaction, немає failure modes |
| Нетрасованість | Вимога висить у повітрі, не декомпозована до функцій | гасло без жодного зв’язку з архітектурою |
Кожен режим ловиться своєю метрикою — про це в Акті V. Без цього розмежування «точність ТЗ» лишається абстрактним заклинанням.
Акт III: Опис варіантів (А що таке точність?)
Ми опиняємося на роздоріжжі. Перед архітектором постає фундаментальне питання: якщо наші специфікації розмиті, то що ми взагалі маємо на увазі під «точністю джерела істини»?
-
Варіант А (Староверський): Намагатися написати «ідеальну» специфікацію людською мовою. Витрачати місяці на вилизування кожної коми в Notion чи Confluence. Спойлер: вона все одно застаріє до вечора, а ШІ все одно знайде там лінгвістичний люфт для генерації архітектурного боргу.
-
Варіант Б (Промпт-анархія): Визнати специфікацію просто набором розмитих побажань. Дозволити ШІ вайбити на повну, грати в «промпт-ролету» і щоранку сподіватися, що черговий автономний рефакторинг випадково не знищить логіку системи.
-
Варіант В (Втеча у формалізм): Якщо жива мова розпливчаста — писати ТЗ мовою, де семантика однозначна за побудовою: логіка першого порядку, TLA+, Alloy, контракти, executable specs. (Романтики згадають міф про санскрит як «ідеально однозначну мову для машин» — залишимо його там, де йому місце: у гарних легендах. Живий санскрит омонімічний і контекстозалежний, як будь-яка природна мова.) Формалізація реально працює — але вона не усуває невідомість, а переносить її: у вибір абстракцій, у повноту моделі, у вартість підтримки трасування. І змушує команду роками вчити нотацію замість проектування реальних систем. Люфт нікуди не зникає — він просто переїжджає туди, де його ще важче побачити.
-
Варіант Г (Стохастичний / Новий): Прийняти той факт, що будь-яке джерело істини має бюджет точності — допуск, який архітектор задає наперед, як задають допуск на деталь у машинобудуванні. Точність ніколи не буде бінарною. Документ має свій рівень ентропії та допустимого люфту, і наше завдання — не молитися на текст як на священний, а задати допуск явно й перевіряти його вимірюванням. ТЗ проходить гейт не тому, що «виглядає нормальним», а тому, що його виміряний люфт вписується в заданий бюджет.
Акт IV: Кульмінація (Епіфанія Метрик)
Індустрія розробки застрягла у нескінченних суперечках про якість коду від ШІ, повністю ігноруючи якість знань на вході. Ми використовуємо термін «точність» як абстрактне заклинання чи гуманітарне побажання.
Без метрик термін «точність джерела істини» повністю втрачає сенс.
Якщо ви не можете оцифрувати рівень неоднозначності вашої моделі чи Markdown-специфікації, ви передаєте ШІ не інструкцію, а квиток у лотерею. Джерело істини без виміряної точності автоматично стає джерелом випадкових результатів. Точність в інженерії ШІ — це не відсутність помилок, це виміряний люфт вхідного документа, звірений із заздалегідь заданим бюджетом.
І кожен режим збою з Акту II отримує свій вимірювальний прилад:
| Режим збою | Метрика | Що вона ловить |
|---|---|---|
| Неоднозначність | $D_{pair}$, $H_{spec}$ — розкид генерацій | розкид можливих реалізацій |
| Неповнота | $D_{const}$ — щільність обмежень | брак машинозчитуваних фактів |
| Нетрасованість | $K_{drift}$ — реляційний дрейф | вимоги, що висять у повітрі |
Акт V: Суха проза (Оцифрування туману специфікацій)
Архітектурний кейс: Як низька точність Markdown-файлу підриває конвеєр ШІ-агентів
Уявімо стандартну Markdown-специфікацію, яку бізнес-аналітик вважає готовим ТЗ:
# Система обробки платежів користувачів
1. Система повинна гнучко приймати транзакції від різних провайдерів.
2. Всі успішні та неуспішні результати операцій необхідно логувати.
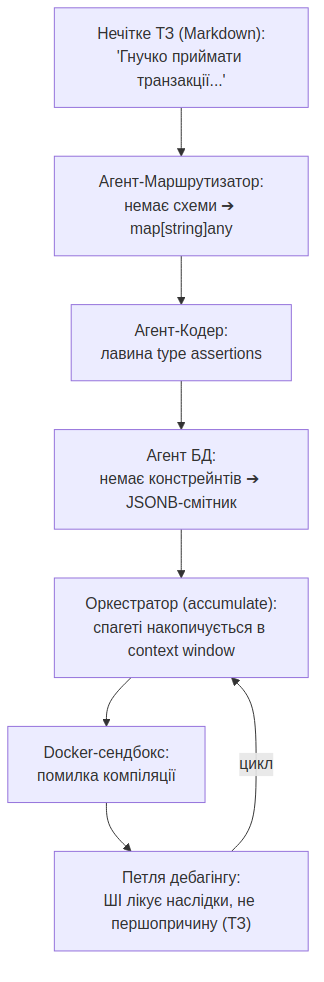
Щільність обмежень цього документа катастрофічно низька: жодної схеми, жодного констрейнту — самі прислівники. Коли ми запускаємо цей файл в автоматизований конвеєр оркестрації (наприклад, заснований на декларативних YAML-топологіях управління агентами), починається лавиноподібний вибух ентропії:
-
Крок 1 (Агент-Маршрутизатор): Бачить слово «гнучко». Оскільки чітких OpenAPI-схем або констрейнтів бази даних у джерелі немає, він обирає найбільш розмиту структуру даних —
map[string]anyв Go. -
Крок 2 (Агент-Кодер): Отримує
map[string]any. Якщо контекстний режим оркестратора налаштований наaccumulate(накопичення повної історії), модель починає генерувати сотні рядків небезпечного коду з постійним приведенням типів (type assertions), намагаючись наосліп вгадати структуру транзакції. -
Крок 3 (Агент Бази Даних): Бачить вимогу «логувати результати». Він створює таблицю в PostgreSQL з полем
JSONB, куди ШІ скидає все підряд, повністю руйнуючи реляційну цілісність даних. -
Колапс конвеєра: На 4-й ітерації ланцюга context window моделі забивається згенерованим спагеті-кодом та розлогими вибаченнями ШІ. Витрата токенів зростає нелінійно. Коли конвеєр намагається зібрати цей Go-код в ізольованому Docker-сендбоксі, компілятор видає помилку невідповідності інтерфейсів. Файл
telemetry.jsonlвибухає рекурсивними помилками. ШІ потрапляє в нескінченну петлю дебагінгу, намагаючись виправити код, який базується на тумані.
Той самий кейс після підняття точності
Той самий бізнес-намір, але з явними обмеженнями:
# Система обробки платежів користувачів
@schema Transaction {
id: UUID,
amount: Decimal(10,2) @constraint(min: 0.01),
currency: String(3) @constraint(pattern: "^[A-Z]{3}$"),
provider: Enum["stripe", "paypal", "adyen"],
idempotency_key: UUID @constraint(unique)
}
1. [REQ-PAY-01] Система валідує вхідний запит за схемою Transaction.
-> [FUN-PAY-01] AcceptTransaction(tx Transaction) (Receipt, error)
2. [REQ-PAY-02] Результати операцій записуються в таблицю payment_logs
(tx_id UUID FK, status Enum["ok","declined","error"], error_code String?, created_at Timestamp).
-> [FUN-PAY-02] LogResult(txID, status, errorCode)
3. [REQ-PAY-03] Повторний запит з тим самим idempotency_key повертає
попередній Receipt без повторного списання.
-> [FUN-PAY-03] state machine: received -> authorized -> captured | declined
Різниця не в обсязі — в кількості ступенів свободи, які ми відібрали в семплінгу моделі. Перший документ дозволяє тисячі несумісних реалізацій; другий — вузький коридор. Саме цю різницю ми зараз навчимося вимірювати.
Інженерні метрики для вимірювання туману
Щоб оркестратор не пускав ШІ-агентів у смертельний цикл, ми зобов’язані спочатку прогнати джерело істини через систему метрик. Почнемо з найдешевшої і найдетермінованішої.
1. Коефіцієнт реляційного дрейфу ($K_{drift}$) — детермінований фундамент
Вимірює кількість ізольованих або «висячих» вимог у графі знань специфікації — тих, що не мають декомпозиції на нижчі рівні системної архітектури. Специфікація розкладається на граф за парадигмою RFLP (Requirements, Functional, Logical, Physical) в одному з двох режимів: strict — детермінований лінтер по явній розмітці ([REQ-*] -> [FUN-*], як у прикладі вище); assisted — легкий AI-агент-парсер зі строгою JSON-схемою на виході (Structured Outputs), коли розмітки ще немає. Граф живе, наприклад, у Neo4j.
Ключова властивість strict-режиму: у контурі вимірювання немає LLM. Це чистий графовий обхід — детермінований, дешевий, відтворюваний. (В assisted-режимі детермінованим лишається лише обхід; якість LLM-екстракції ребер — окремий об’єкт валідації, і метрика успадковує її похибку.) Його можна порахувати сьогодні, без дослідницької лабораторії, і повісити як git hook. Якщо $K_{drift} > 0.2$ (порогове значення — гіпотеза, що калібрується на вашому корпусі специфікацій), щонайменше п’ята частина вашого «джерела істини» — це абстрактні гасла, які ШІ буде змушений реалізовувати на основі чистої вигадки.
2. Синтаксична щільність обмежень ($D_{const}$)
Визначає співвідношення строго формалізованих, машинозчитуваних інженерних фактів до неприв’язаної людської прози всередині того самого RFLP-графа:
\[D_{const} = \frac{\text{Кількість строго типізованих зв'язків (must\_satisfy, performs, flows\_to)}}{\text{Загальна кількість неструктурованих текстових вузлів}}\]Високий $D_{const}$ суттєво звужує простір неконтрольованої інтерпретації: моделі важче вигадати неіснуючі поля, коли кожна сутність затиснута схемою.
Чесне застереження щодо щільності: метрика карає не прозу взагалі, а прозу, не прив’язану до обмежень. Добра специфікація з розгорнутим rationale і trade-off-аналізом матиме нижчу «сиру» щільність, ніж сухий дамп схем — і це нормально. Мета — не максимізувати $D_{const}$, а прибрати вузли, з яких не виходить жодного типізованого ребра. Тому в CI розумніше нормувати щільність на вимогу, а не на документ цілком.
3. Розкид генерацій ($D_{pair}$) та ентропія інтерпретацій ($H_{spec}$)
Найамбітніша метрика: вимірюємо неоднозначність документа через реакцію на нього самої мовної моделі. Родовід прийому чесний і відомий — це self-consistency sampling з арсеналу оцінки невизначеності LLM, тільки розгорнутий у зворотний бік: не на відповідь моделі, а на вхідний документ. Але тут легко збудувати прилад, який вимірює власний шум і видає його за сигнал специфікації, тому — строгий протокол.
Протокол вимірювання:
- Фіксуємо вимірювальну конфігурацію: модель + версія, системний промпт, температура, $N$ семплів. Метрика має сенс лише відносно цієї конфігурації — зміна моделі зсуває всю шкалу.
- Генеруємо $N$ (наприклад, 10) варіантів інтерфейсів системи (Go-структури або схеми міграцій) з одного й того самого ТЗ.
- Нормалізуємо результати до AST і рахуємо попарну схожість (у нашій реалізації — bag of features: типи, поля з типами, сигнатури функцій → косинусна близькість; це структурна схожість згенерованих артефактів, не семантична еквівалентність).
-
Кластеризуємо: результати зі схожістю вище порога (наприклад, 0.95) належать одному класу еквівалентності $x_i$. Тоді $P(x_i) = x_i / N$. - Рахуємо ентропію інтерпретацій:
- Всі $N$ варіантів впали в один кластер ➔ $H_{spec} \to 0$: коридор інтерпретацій вузький.
- Кожна генерація — окремий кластер ➔ $H_{spec} \to \log_2 N$: документ розпливчастий, пускати його в кодогенерацію без доопрацювання — інженерний злочин.
Прилад та його шум (measurement validity). Строго кажучи, ми вимірюємо не внутрішню властивість документа, а умовну ентропію генерації: $H(C \mid S, \theta)$ — розкид артефактів $C$ за даної специфікації $S$ та вимірювальної конфігурації $\theta$ (модель+версія, промпт, температура, парсер, поріг кластеризації). Навіть ідеально однозначне $S$ може давати $H > 0$ — це шум приладу, і він не відокремлюється від «туману документа» жодною формулою: спостережуваний розкид є взаємодією специфікації з приладом, а не сумою незалежних доданків. Тому обов’язковий крок — калібрувальний baseline: проганяємо через той самий протокол еталонну специфікацію з нульовою навмисною свободою. Діагностично значуща не абсолютна величина, а різниця:
\[\Delta H = H(C \mid S, \theta) - H(C \mid S_{base}, \theta)\]Мета «підняття точності ТЗ» у цих термінах — знизити умовну ентропію генерації до рівня підлоги приладу.
Два практичні нюанси:
- Температура. Висока температура (1.0) максимізує саме шумовий компонент. Тому режими треба розділяти:
temp ≈ 1.0— стрес-тест межі інтерпретацій («наскільки далеко модель може втекти від тексту»),temp ≈ 0.3–0.5з більшою кількістю семплів — робоче вимірювання властивості документа. Пороги quality gates визначаються при робочій температурі; числа зі стрес-тесту в gates не підставляються. - Малі вибірки. Оцінка ентропії з $N=10$ семплів зміщена вниз (класичний bias plug-in-естиматора), а стеля обмежена $\log_2 10 \approx 3.32$ біт — документ систематично виглядає точнішим, ніж є; для порівнянь між вибірками зручна нормована форма $H/\log_2 N \in [0,1]$. Практичний висновок нашого ж експерименту: робочою метрикою варто зробити середню попарну AST-відстань $D_{pair} = 1 - \overline{\text{sim}}$ — вона неперервна, не сатурує і не потребує порога кластеризації. Ентропія кластерів залишається ordinal-сигналом («один кластер чи багато») та інструментом трендів.
Визнання шуму приладу — не слабкість методології, а те, що відрізняє інженерну метрику від маркетингової.
Дисперсія: дефект чи ресурс? (Два режими)
Досі ми говорили про дисперсію як про ворога. Це правда рівно наполовину, і чесна методологія мусить розвести два режими:
- Зона реалізації. Специфікація описує систему, в якої є «правильна» відповідь: платіжний конвеєр, схема БД, контракт API. Тут дисперсія — ризик, її гейтимо: висока $\Delta H$ блокує кодогенерацію й повертає ТЗ автору.
- Зона пошуку. Правильної відповіді ще немає: дизайн нового модуля, вибір архітектурного підходу. Тут та сама дисперсія — ресурс: розкид генерацій працює як мутаційний оператор еволюційного пошуку, а помилки моделі — як дешеві розвідувальні зонди. Дисперсію тут культивуємо свідомо й на ізольованому полігоні.
Стохастична інженерія — це не боротьба з ентропією, це вибір режиму: де її душити, а де запрягати. Оркестратор має знати, в якій зоні працює, і застосовувати протилежні політики.
Метрики в контурі оркестратора
Метрики без наслідків — це дашборд, на який ніхто не дивиться. Ось як вони керують конвеєром:
quality_gates:
- metric: D_pair # 1 − mean pairwise sim; робоча метрика, зона реалізації
max: 0.30
action: block_and_request_clarification
- metric: delta_H # ordinal-контроль: один кластер чи багато
max: 0.75
action: block_and_request_clarification
- metric: D_const
min: 0.35
action: enrich_specification # агент пропонує @schema-стаби, автор підтверджує
- metric: K_drift
max: 0.2
action: require_traceability_mapping
policies:
- when: D_pair < 0.15 and D_const > 0.5
set: { reasoning_effort: low } # ТЗ затиснуте — економимо токени
- when: { zone: exploration }
set: { entropy_gates: off, sandbox: isolated } # зона пошуку: дисперсію культивуємо
І замкнений цикл замість одноразового гейту:
- виміряти ➔ 2. знайти джерела ентропії (кластери $H_{spec}$ вказують, де саме текст розповзається) ➔ 3. запропонувати уточнення ➔ 4. переміряти ➔ 5. лише тоді пускати агентів у кодову базу.
Нотатка про реалізацію
Повноцінний $D_{const}$ рахується на RFLP-графі, але перший рубіж дешевший: лексичний сканер у hot path інжесту, який по маркерах розмітки (@schema, @constraint, [REQ-*]) відсіює відверто «пусті» документи ще до побудови графа. У нашому Go-бекенді це один прохід по байтовому буферу з пулінгом (sync.Pool) — мікросекунди на документ, тож метрику можна вішати git hook-ом на кожен коміт специфікації без жодного впливу на pipeline. Деталі реалізації — тема окремого, суто інженерного матеріалу.
Порівняльна таблиця парадигм проектування
| Параметр архітектури | Стохастична інженерія (Варіант Г) | Традиційний детермінізм (Варіант А) |
|---|---|---|
| Статус джерела істини | Динамічний артефакт із заданим бюджетом точності, звіреним вимірюванням | Статичний документ, що імітує абсолютну істинність |
| Метрика вхідних даних | $D_{pair}$, $\Delta H$ (розкид понад шум приладу), $D_{const}$, $K_{drift}$ | Суб’єктивне рев’ю людиною («нормальне ТЗ») |
| Режим оркестратора | Коригування reasoning effort і gate-політик за виміряним люфтом та зоною (реалізація/пошук) | Статичні лінійні виклики моделей без урахування люфту |
| Дисперсія виходу ШІ | Керований параметр: гейтиться в зоні реалізації, культивується в зоні пошуку | Критичний збій, що потребує ручного втручання |
| Роль розробника | Архітектор/диригент розподілів імовірностей та шлюзів валідації | «Друкар коду», що вручну закриває дірки в ТЗ |
Межі підходу (щоб нас не звинуватили в новому культі)
Методологія не претендує на срібну кулю, і ось де вона чесно закінчується:
- Метрики прив’язані до приладу. $H_{spec}$ залежить від моделі, промпту й температури. Це не абсолютна властивість документа — це його властивість відносно вимірювальної конфігурації. Порівнювати числа між різними моделями без перекалібрування — безглуздо.
- Низька ентропія ≠ правильність. Документ може детерміновано вести всіх агентів до одного й того самого хибного бізнес-рішення. Метрики міряють люфт, а не істину.
- Метрики геймляться. Накидати
@schema-тегів без змісту — і $D_{const}$ зросте, не покращивши нічого. Частковий контрзахід — $K_{drift}$: він вимагає реальних ребер трасування, а не маркерів, тож геймити його дорожче, ніж просто написати нормальне ТЗ. - Пороги — гіпотези. Значення 0.2, 0.35, 0.75 у прикладах — стартові точки для калібрування на власному корпусі специфікацій, а не константи природи. Процедура калібрування: зібрати історичні спеки, розмітити їх downstream-наслідками (rework, компіляційні фейли, кількість агент-ітерацій, токен-бюджет) і підбирати пороги проти цих наслідків при робочій температурі.
- Деякі задачі потребують туману. Продуктова розвідка, дослідження нового домену — там передчасна детермінізація шкодить. Для цього й існує зона пошуку.
Sanity check: проведений експеримент
Ми не залишили це обіцянкою — прогнали протокол наживо. П’ять специфікацій: туманне ТЗ платежів (перший приклад), те саме після підняття точності (другий приклад), еталон із повністю заданими Go-типами (шумова підлога) — плюс два реальні docs/requirements.md з живих проєктів (session-indexer, 125 рядків прози з FR-тегами, і ragivka, 80 рядків формалізованих NFR). Два незалежні прилади, той самий протокол:
| Конфігурація | Прилад A | Прилад B |
|---|---|---|
| Модель | qwen3-coder:30b (локальна, Ollama) | kimi-k2.7-code (Ollama cloud, think=off) |
| Температура / N | 1.0 / 10 | 1.0 / 10 |
| Порівняння | Go AST → cosine → single-linkage | те саме |
Результати ($H$ у бітах, стеля $\log_2 10 = 3.32$; sim — середня попарна AST-схожість):
| Специфікація | A: sim | A: $H_{@0.95}$ | B: sim | B: $H_{@0.95}$ |
|---|---|---|---|---|
| baseline (еталон) | 1.000 | 0.00 | 1.000 | 0.00 |
| sharp (точне ТЗ) | 0.730 | 1.77 | 0.682 | 3.32 ($H_{@0.80}$=2.12) |
| fog (туманне ТЗ) | 0.492 | 3.32 (стеля) | 0.242 | 3.32 |
| real: session-indexer | 0.524 | 3.32 | 0.258 | 3.32 |
| real: ragivka | 0.282 | 3.32 | 0.278 | 3.32 |
Що це дало, крім підтвердження базового ранжування (за попарною схожістю — на обох приладах; за $H_{@0.95}$ — лише на приладі A, див. п.3):
- Copy-підлога виявилася нульовою на обох приладах: усі 10 генерацій еталона ідентичні аж до AST. Чесне уточнення: наш еталон містить готові Go-типи, тож це нижня межа шуму на задачі транскрипції, а не універсальна підлога приладу. Повний baseline-suite (зокрема формалізована спека тією ж нотацією, без готових типів) — наступний крок, і $H=0$ на ній не гарантований.
- Точне ТЗ не впало до нуля ($H_{sharp}=1.77$): модель по-різному мапить
Decimal(10,2)у Go (float64 / int-копійки / decimal-ліба). Метрика показала пальцем рівно на те місце, де специфікація залишила люфт. Це і є її робота. - Метрика справді instrument-relative — числами: ранжування за попарною схожістю збереглося на обох моделях, абсолютна шкала зсунулась (kimi розкиданіший всюди: fog 0.242 проти 0.492). А от ранжування за $H_{@0.95}$ на приладі B зламалось — sharp сатурує разом із fog (3.32) і розділяється лише при порозі 0.80. Поріг кластеризації — повноцінна частина приладу; ordinal-висновки за $H$ без його калібрування нестабільні, що додатково аргументує $D_{pair}$ як робочу метрику.
- Сатурація стелі на реальних документах: обидва живі requirements.md вперлися в $\log_2 10$ — кожна генерація в окремому кластері. Для документів системного масштабу $H_{@0.95}$ при $N=10$ перестає розрізняти, дискримінує середня попарна відстань. І вона принесла інверсію інтуїції: формально розмічений ragivka (NFR-теги, числові констрейнти) розкиданіший (0.282) за прозовий session-indexer (0.524) — бо NFR затискають quality attributes, а не структуру типів, і масштаб системи домінує над формальністю розмітки. Контрольний дослід підтвердив механізм — на обох приладах: коли до requirements додали architecture- і concepts-доки (структурні якорі замість quality-гасел), схожість генерацій зросла з 0.282 до 0.402 на приладі A і з 0.278 до 0.393 на приладі B. Приріст майже ідентичний (+0.120 / +0.115) — дозоване збільшення точності входу дає вимірюваний відгук, і це не артефакт однієї моделі. (Чесна межа: інверсія ragivka/session-indexer чітка лише на приладі A; на B відповідні числа 0.258 і 0.278 — в межах шуму, а різниці такого масштабу при $N=10$ потребують bootstrap-інтервалів. Її позначаємо як спостереження для перевірки, не як висновок.)
- Режим reasoning — частина вимірювальної конфігурації. Перший прогін приладу B мовчки згорів: thinking-режим з’їдав увесь токен-бюджет на складних специфікаціях, лишаючи порожній вивід — причому збій корелював зі складністю входу, тобто спотворював би порівняння систематично, а не шумом. Те саме з token cap: обрізана генерація виглядає як «ще один кластер», хоча це артефакт стелі приладу. Протокол мусить фіксувати think-режим і ставити кап вище природної довжини виходу. (З 120 фінальних генерацій відкинуто 1 синтаксично невалідну; протокол: регенерація до N валідних із фіксацією discard count. Сама частка невалідних — invalid rate — теж сигнал: туманна чи завелика спека підвищує ймовірність зламаного виводу, тож її треба звітувати, а не ховати регенерацією.)
Драбина тверджень (що ми довели, а що — ні)
- Підтверджено даними: різні специфікації дають вимірювано різний розкид генерацій за фіксованого приладу; схеми і трасування звужують його; додавання структурних доків дає вимірюваний відгук, відтворений на двох незалежних приладах (+0.120 і +0.115 sim).
- Підтверджено sanity-check, але не узагальнено: стабільність ранжування за $D_{pair}$ між двома приладами; інверсія «формальність розмітки ≠ точність» на реальних доках.
- Гіпотези, що потребують корпусу: конкретні пороги gates; зв’язок метрик із downstream-наслідками (rework, компіляційні фейли, токен-бюджет); переносимість порогів між моделями.
Впровадження цієї методології дозволяє команді вийти з інфантильного стану очікування «ідеального коду від ШІ». Ми тверезо оцінюємо рівень туману на вході, оцифровуємо його, звіряємо з бюджетом точності — і адаптуємо наш Go-бекенд та конвеєри оркестрації під реальну, виміряну точність наших джерел знань.
Дані та відтворюваність
Повний набір експериментальних даних — шість специфікацій, 120 згенерованих файлів (плюс discarded-семпли для провенансу), генераційні скрипти та AST-аналізатор на Go — лежить у каталозі sanity/ поруч зі статтею; конфігурації обох приладів і всі «граблі» протоколу (think-режим, num_predict, num_ctx) зафіксовані в sanity/README.md. Виміряні живі проєкти: session-indexer та ragivka — оцінки їхніх специфікацій продубльовані в самих репозиторіях (docs/spec-dispersion-assessment.md).